

招聘之星诞生于2010年,志立于帮助企业HR人员从繁琐的招聘工作中解脱出来,合理的简化招聘流程,有效的筛选简历,高效的获得人才,合理的管理人才。
招聘之星软件具备传统邮件客户端(Foxmail、Outlook)全部的邮件收发管理功能,能够满足用户的日常邮件操作应用。
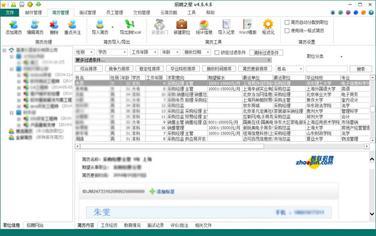
支持任意格式的简历导入,自动解析邮件简历内容,并可以按照10几个维度进行过滤、排序、搜索,整个过程软件全自动完成。
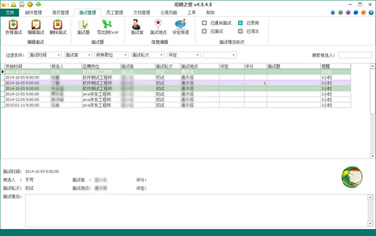
帮您轻松安排和管理招聘工作计划,其中包括,面试时间、面试地点、面试官、面试轮次、面试题、面试记录等信息设置。
员工管理模块,涵盖有档案管理中各种常见项目的录入,包括员工家庭成员信息、办公用品领用信息、员工培训记录、员工调薪记录、员工奖励等,并在不断扩充中。
文档管理模块采用所见即所得的操作方式,对于用户日常的本地文档文件或网页浏览内容进行快速收集备份并分类保存,便于以后的阅读和检索。
为用户提供了安全可靠,便捷易用的在线企业人才库解决方案,无论您是个人还是企业,都可以免费使用云简历酷服务,建立隶属于自己的专业人才库。





“招聘之星”是集邮件管理、简历管理、人事管理、文档管理、云存储于一体的全功能、智能化人力资源系统解决方案。
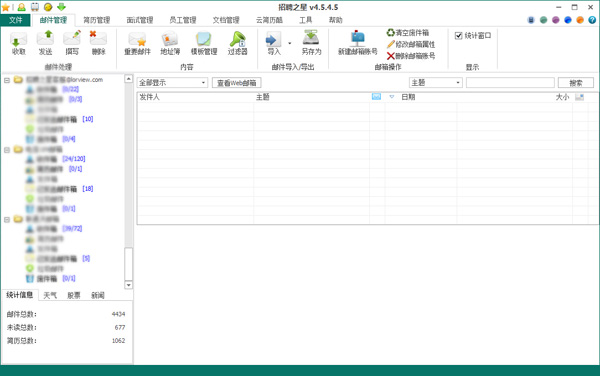
招聘之星的邮件管理可以作为电子邮件客户端接收和发送电子邮件。
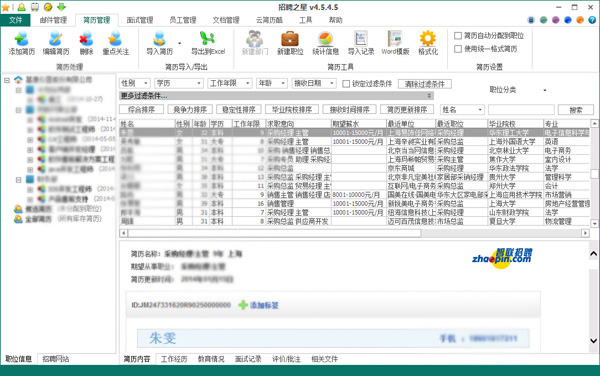
招聘之星的简历管理模块可以自动的处理一切简历相关的工作。
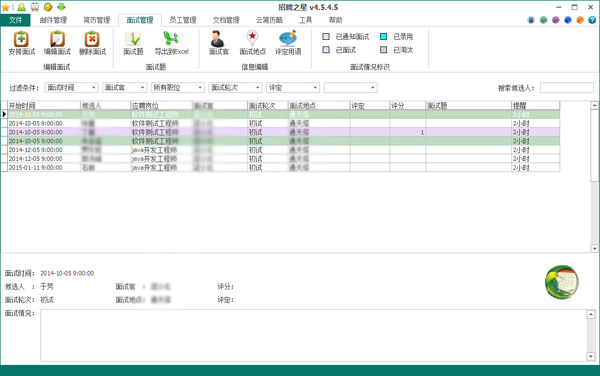
招聘之星的面试管理可以高效的组织安排面试工作,使海量面试工作变得井井有条。
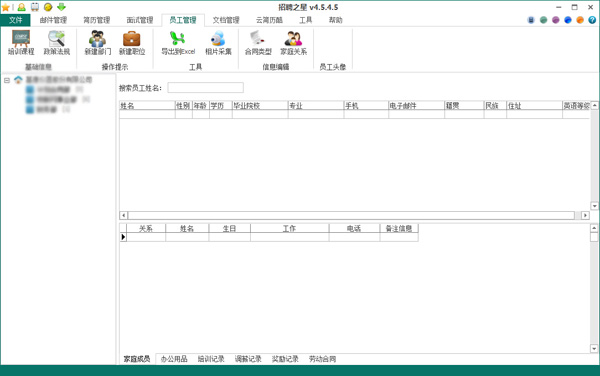
招聘之星的员工管理模块,涵盖有档案管理中各种常见项目的录入,包括员工家庭成员信息、办公用品领用信息、员工培训记录、员工调薪记录、员工奖励等。
招聘之星的文档管理模块,是帮助用户快速存储和管理摘录文档。当用户在网上阅读文章资料时,遇到感兴趣的内容,可以直接将其拷贝存入文档管理,无论是以后的阅读和检索,都具有极大的便利。
我们致力于提供人力资源领域最优秀的软件产品与服务,为广大企业提供前所未有的便捷体验及全新的工作方式。我们不断创新并专注于HR领域,持续为客户提供优质的软件产品是我们永远的目标。
Copyright © 2010 lorview.com All Rights Reserved 京ICP备2022028937号





